- Pre-Process Signal: In this block, I apply the "pre-gain", which is the amount of gain that will be applied when the compressor is in its linear regime. Also in this block, I use a high-pass filter to remove any DC offset in the audio signal.
- Level Estimator: For the compressor to vary the gain based on the loudness of the signal, it needs to first estimate the loudness of the signal. That's what this block does.
- Gain Calculator: Using the estimated loudness, this block calculates how much to reduce the gain of the system. It calculates the desired gain reduction knowing the "compression ratio" and "compression threshold" that have been supplied by the user. It also smooths the compressed gain value through time via "attack" and "release" time constants that have been supplied by the user.
- Apply Gain: Once the desired compressed gain value has been calculated by the side-chain, this block applies the gain to the audio signal.

Algorithm Parameters: In the signal flow diagram below, I show the algorithm parameters that are available for the user to set. The main tricky part is how to set the time constant for the Level Estimator. By default, I have this value always scale itself to be 20% of the time constants that the user has set for the Gain Calculator block. If you don't like this default behavior, you can specify your own value using the method setLevelTimeConst_sec().

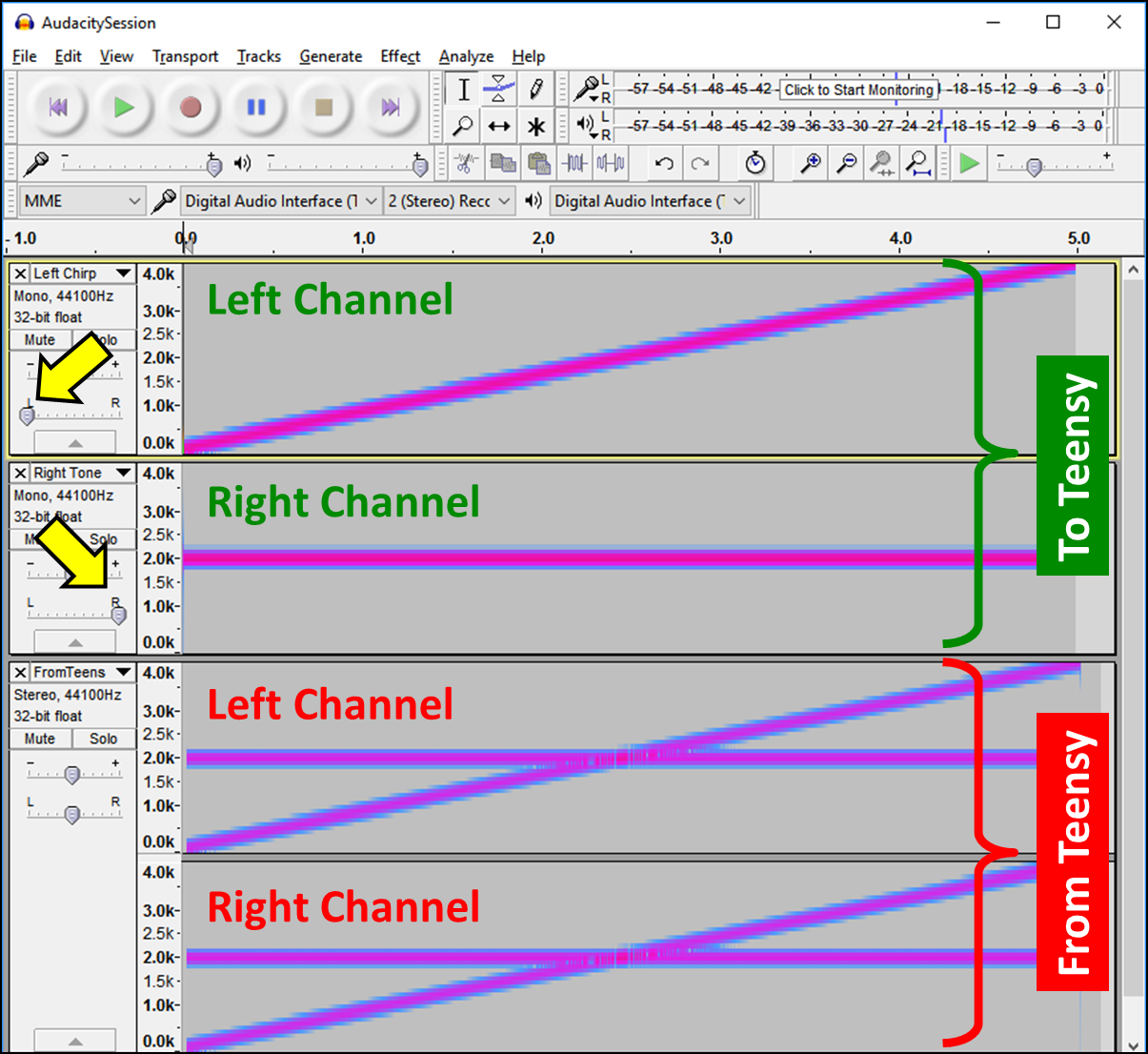
- USB Audio: For my testing, I chose to send and receive audio over the USB link, instead of via analog audio cables. See this post, if you want more info on how to use the Teensy's USB Audio link. To enable USB audio in this sketch, set DO_USB to a value of one.
- Fast or Slow: Another choice is how to set the values for the compressor's parameters. In my example, I have two sets of parameters. One set gives a "fast" compressor response that is appropriate for quick limiting of very loud sounds. The other set of values gives a "slow" response that can be used as a automatic volume control. For my testing, I chose to use the "fast" response, as shown below.

Test Setup: For my testing, I'm using my breadboard prototype of my Teensy Hearing Aid, which is just a Teensy 3.6 with the Teensy Audio Board (plus microphones, battery, and Bluetooth module, which are not relevant to this test). I've got it plugged into my laptop via USB, which is also used to send and receive audio to the Teensy via the Teensy's ability to do USB Audio. On my laptop, I'm using the Arduino IDE to set the compressor's parameters (again, I'm using the "fast" configuration) and I'm using Audacity to send the audio to the Teensy and to record the audio returned by the Teensy.

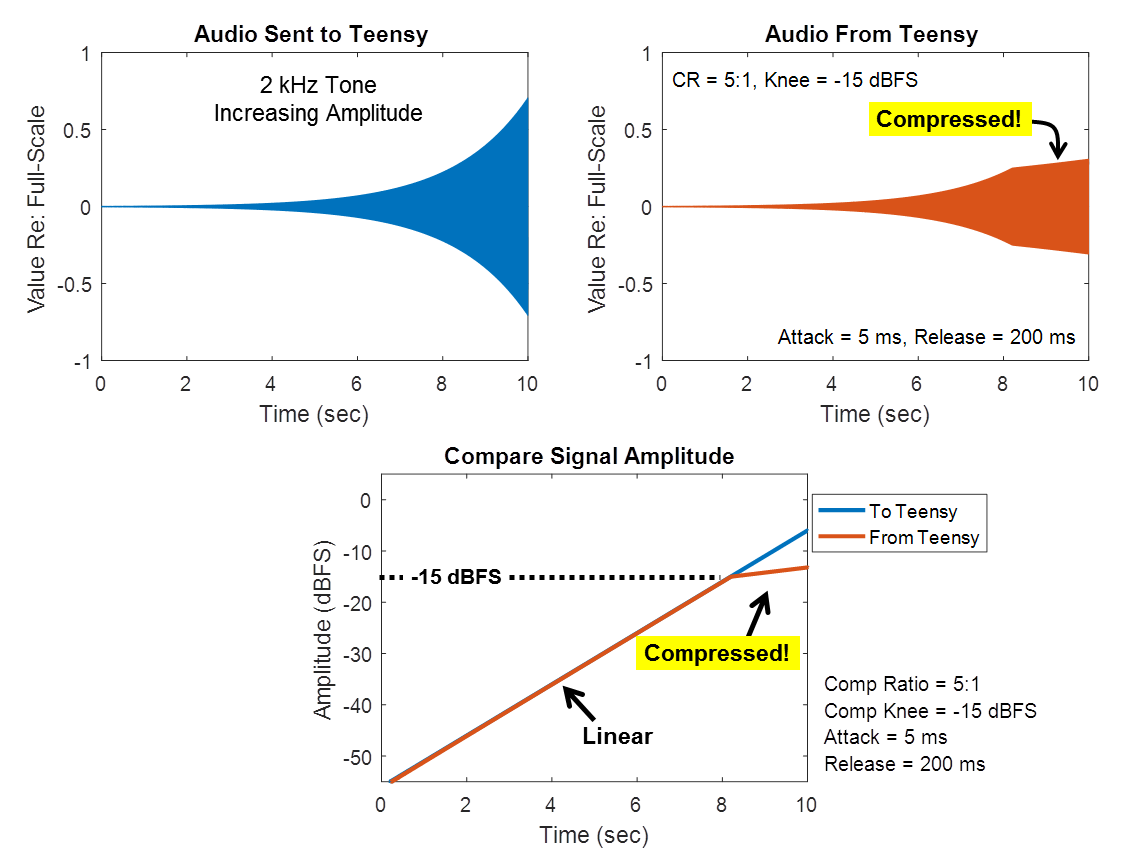
Testing, Amplitude Sweep: For my first test, I generated a steady 2kHz tone whose amplitude increases from quiet to loud at a rate of about 6 dB/sec (my test signals are shared here). This is the signal that I'm sending to the Teensy (also shown in blue in the figure below). When sending this signal, the compression algorithm on the Teensy returns the signal shown in orange. If you look at the loudest portion of the audio (starting around time = 8 seconds) the amplitude of the orange output signal looks to be squashed compared to the blue input signal. This is the effect of the compressor! It successfully reduced the dynamic range of the audio, as intended.
Testing, Step Changes in Amplitude: Another important question is whether the compressor is responding at the correct speed to changes in signal amplitude. To answer this question, I generated a test signal with instantaneous step changes in amplitude, as shown in blue in the figure below. The compressor's response is shown in orange.

Next Steps: With the dynamic range compressor working correctly (and sounding pretty good when used with my Teensy Hearing Aid's microphones and my headphones), I'm well on my way to completing the signal processing hardware and software for a very basic hearing aid. The main component that I'm still missing is some sort of frequency compensation to increase the gain on the frequencies that the listener needs to hear better, while reducing gain on those frequencies that the listener already hears well enough. Stay tuned!
Follow-Up: This algorithm converts to dB and back. When doing the log10(x) and pow(10,x), be sure to call the correct versions and they'll run *much* faster. Check it out here.